Image Reconctruction
Introduction
This blog is dedicated to the project for the course on Deep Representation Learning (IFT6266) taught by Aaron Courville at Université de Montréal.
Given images of size 64x64, we mask the central region of size 32x32. The goal of this project is to generate that missing central region conditioned on the outer border of the image and a caption describing the content of the image.
Proposed Architecture
We implemented a feed-forward auto-encoder architecture with Tensorflow, which is shown in figure 1.
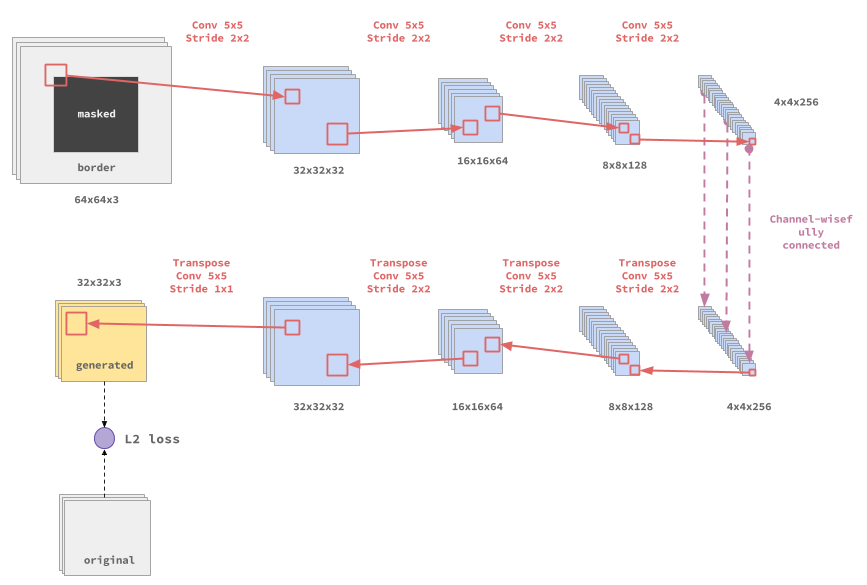 |
| figure 1: Architecture of our auto-encoder |
Implementation details
The encoder uses a sequence of 4 down sampling 5x5 convolutions with strides of 2x2 to extract a 4x4x256 representation of the input image, while the decoder uses a sequence of 4 up sampling 5x5 convolutions of strides 2x2 to reconstruct the masked region. Each convolution is followed by a batch normalisation before the activation function. Inspired by [1], we used a channel-wise fully connected layer between the encoder and the decoder, to let information flow throughout each feature map and thus have each node be aware of the context of the image.Down sampling and skip-connections
The issue with down sampling is that we loose information that may be useful later, in the decoder, for the reconstruction of the masked area. To prevent that from happening, we used skip-connections between layers of the encoder and corresponding ones of the decoder. |
| Skip-connections between layers |
Adversarial + Reconstruction
We used L2 reconstruction loss coupled with adversarial loss. We weighted them respectively with 0.8 and 0.2We expected the discriminator to help our model generate real-like images, while the L2 would help keep some consistence with the target image.
The discriminator is made of a sequence of 4 down sampling 5x5 convolutions with 2x2 strides building a 4x4x256 representation of its input image. Follows a linear layer connecting all 4x4x256 feature units and producing the logits. The discriminator operated over whole images (64x64) not just over the central region (32x32).
 |
| Architecture of the discriminator |
Adding captions and embeddings
To incorporate the captions, we used a pre-trained model to generate embeddings of size 1024 for the image captions. Since each image had several captions, we created a copy of an image for each of its captions.
The architecture of the model is slightly modified to use these embeddings as shown in figure <to be determined> :
The architecture of the model is slightly modified to use these embeddings as shown in figure <to be determined> :
- In the auto-encoder : The embeddings are first linearly projected into a lower dimensional representation (we practically used 256). The vectors obtained are tiled and reshaped, then concatenated to the output of the channel-wise fully connected layer (reshaped to 4x4x256) along the feature axis. We didn't try to concatenate them prior the channel-wise fully connected layer, and perhaps that might have influenced the results. It remains to be tested.
- In the discriminator : We use another linear projection of the embeddings (256) which we tile and reshape, then concatenate to the output of the last convolution layer (4x4x256) along the feature axis.
 |
| Auto-encoder with embeddings |
 |
| Discriminator with embeddings |
The choice of activation function
We considered experimenting with the exponential linear activation or the gated activation, but rather did with the rectify linear activation function for simplicity.
Regularisation and Optimisation
For our experiments we haven't used any regularisation scheme, not even dropout, since other work with the same data set have shown no improvement due to dropout. We considered adding it in later experimentation. For the optimisation during training, we used the Adam optimiser and clipped the gradient with a max norm of 1.
Results
 |
| Results obtained without captions embeddings |
 |
| Results obtained with captions embeddings |
The model reconstructs blurry images, but seemingly consistent with the context of the target image. It fails to reconstruct sharp details though. Perhaps if the model had more capacity could it reconstruct sharper details of the images. Besides, there is a visible discontinuity between the generated area and the border area of the results.
We didn't notice any difference between the reconstruction with and without caption embeddings.
Possible improvements
It would be interesting to investigate other losses that could force the model to reconstruct a masked area continuous at its border with the outer area of the image.
Inspired by the model DRAW, we believe it would be interesting to combine the benefits of deep convolutional structures with attention and recurrence, in order to focus on local properties of images and reconstruct the masked area in an iterative manner.
Conclusion
We implemented a model to reconstruct the masked central region of an image. Though our model seems to have a vague idea of how the image should be filled (blurry shapes) it fails to reconstruct sharp features. Besides, we have not been able to highlight any added value from the usage of the captions.
References
- Pathak, Deepak, et al. "Context encoders: Feature learning by inpainting." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Ryan Kiros, Ruslan Salakhutdinov, Richard S. Zemel. "Unifying Visual-Semantic Embeddings with Neural Languag Models." arXiv preprint arXiv:1411.2539 (2014).
- Clevert, Djork-Arné, Thomas Unterthiner, and Sepp Hochreiter. "Fast and accurate deep network learning by exponential linear units." arXiv preprint arXiv:1511.07289 (2015).
- van den Oord, Aaron, et al. "Conditional image generation with pixelcnn decoders." Advances in Neural Information Processing Systems. 2016.
Comments
Post a Comment